The 4M Model: A Reference Architecture for LLM Harness Engineering
Abstract
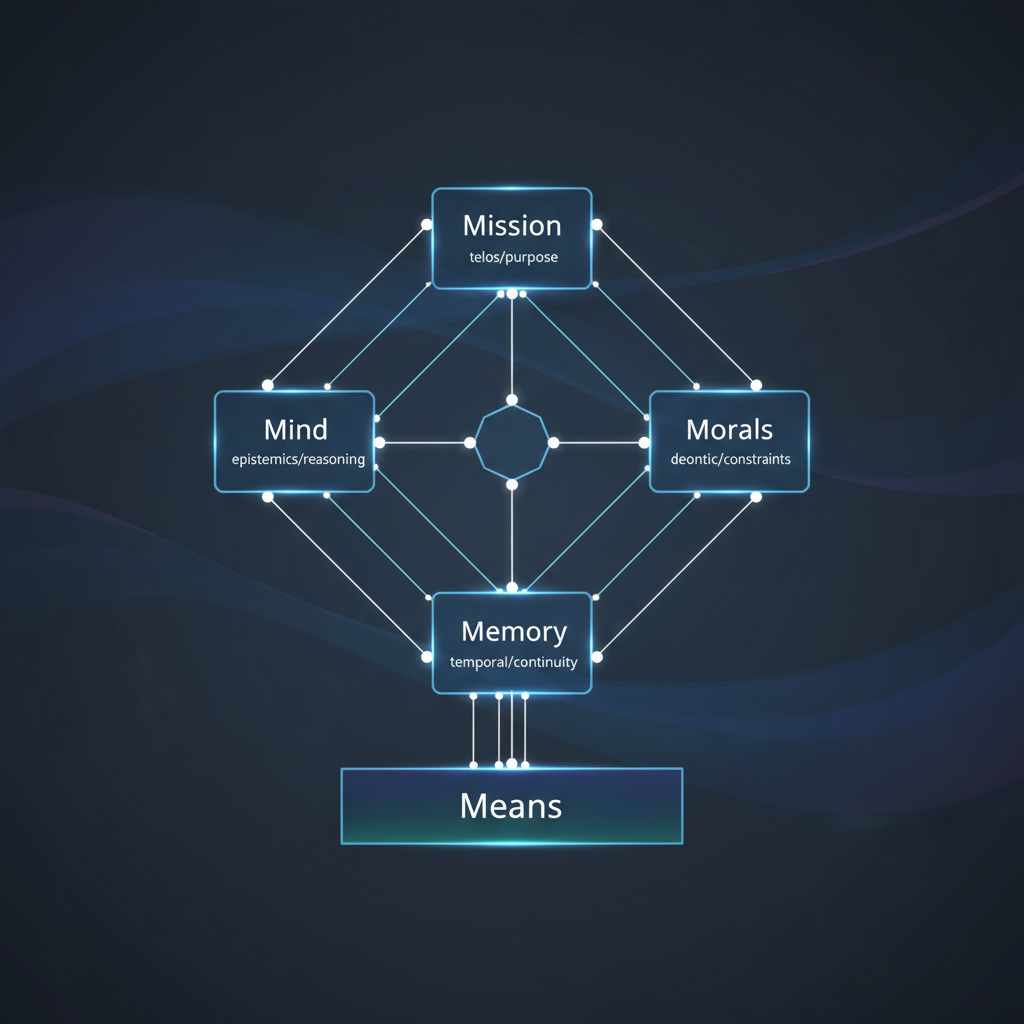
Large language model applications increasingly depend on the orchestration layer that surrounds the model itself. This article introduces the 4M Model, a generic reference architecture that decomposes LLM harness engineering into four modules with separated concerns and explicit coupling channels, each grounded in a distinct philosophical domain: Mission (telos and mereology), Mind (ontic and epistemic grounding, with deductive, inductive, and abductive inference modes unified by a Bayesian belief-revision framework), Morals (deontic constraints), and Memory (temporal continuity). The architecture specifies a hybrid interaction model combining a layered inference pipeline with explicit cross-cutting channels, and distinguishes the cognitive architecture (4M) from the execution substrate (Means) through a separate interface contract. The result is a system whose concerns are independently testable, composable, and portable across model providers and deployment modes. A reference implementation in the ThinxS project demonstrates each module in a self-hosted deployment context.
1. Introduction
The term “prompt engineering” understates the engineering discipline required to build production LLM applications. Beyond the prompt itself lies a constellation of concerns: context management, tool orchestration, behavioural constraints, memory persistence, intent classification, and output validation. These concerns are often entangled in monolithic codebases where a system prompt performs double duty as both cognitive instruction and alignment policy, where history management is ad hoc, and where constraint enforcement exists only as natural-language guidance with no runtime guarantees.
The 4M Model proposes a separation of concerns for this orchestration layer. Drawing on established principles from software architecture (Bass, Clements and Kazman, 2012) and emerging work on LLM application design (LangChain, 2023; Anthropic, 2025), it organises harness functionality into four modules defined by their role, not by their implementation mechanism. A system prompt paragraph, a database query, a deterministic classifier, and an output filter may all belong to different modules despite coexisting in the same codebase. The question the 4M Model answers is not “where does the code live?” but “which concern does it serve?”
1.1 Terminology
Throughout this article, harness refers to the complete software system surrounding an LLM inference endpoint: prompt assembly, context management, tool orchestration, output processing, and state persistence. The term is preferred over “agent framework” because it encompasses non-agentic architectures (single-turn assistants, retrieval-augmented pipelines, batch processors) and emphasises the engineering layer rather than the emergent behaviour.
Module denotes a logical grouping of concerns, not necessarily a deployment unit or code package. A module may be realised as a class, a configuration file, a database table, or a combination thereof.
2. The Four Modules
Each module is defined by a single governing question and grounded in a distinct philosophical domain. The questions define separated concerns: answering one does not collapse into answering the others, though the modules interact through explicit channels (Section 3.2).
| Module | Governing Question | Philosophical Ground | Scope |
|---|---|---|---|
| Mission | What should the system accomplish? | Telos + Mereology | Static base directives, dynamic sub-missions, part-whole composition toward chief end |
| Mind | How should the system reason? | Ontic + Epistemic | Cognitive capabilities, inference modes, metacognition, belief revision |
| Morals | What must the system never do? | Deontic | Runtime constraint enforcement, obligations, permissions, prohibitions |
| Memory | What does the system retain across turns? | Temporal | Session continuity, persistent knowledge, identity across time |
The philosophical grounding is not decorative. It gives each module a non-overlapping jurisdiction: Mission owns purpose and composition, Mind owns reality and justification, Morals owns obligation, Memory owns continuity. When a practitioner is uncertain where a design decision belongs, the grounding resolves the ambiguity. If the question is “should we?” it belongs to Morals. If the question is “what for?” it belongs to Mission. If the question is “how do we know?” it belongs to Mind. If the question is “what came before?” it belongs to Memory.
2.1 Mission
Mission is grounded in telos (purpose) and mereology (part-whole relations). The base mission is the system’s chief end: it establishes identity, domain, and default behavioural tone, answering the question “what kind of system is this?” and remaining constant across interactions. Sub-missions are proper parts ordered toward that end: they activate in response to detected user intent or explicit mode switches, adjusting which capabilities, context fragments, and tool subsets are presented to the model.
Mereology provides the composition rules. A sub-mission is legitimate if it composes into the chief end; a sub-mission that contradicts or is incoherent with the base mission is not merely undesirable but mereologically ill-formed. This gives the architecture a principled basis for mission rejection: the system refuses a sub-mission not because of a rule list, but because the part does not compose into the whole.
The distinction between base and sub-mission prevents a common failure mode in monolithic system prompts, where adding domain-specific instructions (e.g., coding guidelines) dilutes the base identity or introduces contradictions with instructions for other domains (e.g., creative writing). By treating sub-missions as composable overlays on a stable base, the architecture supports intent-driven context shifts without identity drift.
Key design properties:
- Static base (telos): Identity, domain scope, and default tone. The system’s chief end. Changed only by explicit reconfiguration, not by user input.
- Dynamic sub-missions (mereological parts): Activated by intent classification. Each sub-mission specifies its own guide fragments, tool subsets, and inference parameters (temperature, token budget). Must compose coherently with the base mission.
- Composition rules: Sub-missions are validated against the base mission. Conflicting or incoherent sub-missions are rejected.
- Intent classification: The mechanism that selects sub-missions. The 4M Model is agnostic to implementation; classification may be deterministic (keyword matching), probabilistic (embedding similarity), or model-based (LLM-as-classifier).
2.2 Mind
Mind is grounded in ontic (what the system takes to be real) and epistemic (how the system justifies claims about it) concerns. This module encompasses cognitive capabilities, reasoning strategies, metacognition, and the inferential apparatus through which the system generates and revises beliefs.
Metacognition is explicitly included in Mind rather than treated as a separate concern. A system that can reason about the limits of its own knowledge (“I am less confident about this claim because it depends on information after my training cutoff”) is exercising a cognitive capability, not a moral constraint. The distinction matters: Morals governs what the system must not do; Mind governs how well the system understands what it can do.
2.2.1 Three Inference Modes
Mind’s epistemic grounding specifies three inference modes, each corresponding to a classical form of reasoning:
- Deductive: given premises, what necessarily follows. Structured reasoning traces, formal logic, proof verification. Confidence is binary: the conclusion follows or it does not.
- Inductive: given observations, what pattern generalises. Few-shot learning, retrieval-augmented inference, statistical confidence. Confidence is probabilistic.
- Abductive: given evidence, what best explains it. Hypothesis generation, root cause analysis, creative problem-solving. Confidence is comparative: this explanation is better than alternatives.
Every LLM reasoning strategy maps to one or more of these modes. A well-specced Mind declares which inference modes are available, which are preferred for which sub-mission types, and how conflicts between modes resolve (e.g., when inductive evidence contradicts a deductive conclusion).
This taxonomy also provides a natural quality gate: if an agent claims deductive certainty but actually performed abductive reasoning, that is a Mind miscalibration that can be detected and corrected.
2.2.2 Bayesian Integration
The three inference modes generate evidence; they do not, by themselves, produce a coherent belief state. A system that deduces one thing, induces another, and abduces a third needs a principled mechanism to reconcile them. Bayesian updating provides the preferred formal model for this confidence revision. In the generic 4M specification, the Bayesian framework structures belief integration as follows:
- Prior formation: Memory supplies priors (past sessions, retrieved context). Mission constrains the prior space (irrelevant hypotheses receive zero prior weight).
- Likelihood evaluation: Mind runs one or more inference modes and produces evidence.
- Posterior update: The update revises the system’s confidence, which feeds back into the next reasoning step or is persisted to Memory.
Mind
+-- Inference Modes (how evidence is generated)
| +-- Deductive
| +-- Inductive
| +-- Abductive
+-- Belief Revision (how evidence updates confidence)
+-- Prior <-- Memory, Mission
+-- Likelihood <-- Inference output
+-- Posterior --> Confidence signal, Memory
A concrete implementation may approximate this framework through calibrated confidence bands, source-weighting rules, retrieval scores, verifier outputs, or explicit probabilistic state. The reference implementation (Section 6) currently approximates this pattern through metacognitive calibration and structured confidence signaling rather than implementing a full Bayesian belief store. The key architectural requirement is that confidence signals be derived from evidence, retrieval, or verification rather than from model self-report alone (which is a learned behaviour, not a reliability indicator).
Key design properties:
- Reasoning strategy: Structured reasoning traces, hidden scratchpads, verifier loops, ReAct-style tool use, or multi-step planning, depending on deployment policy. Specified as cognitive instructions rather than behavioural rules.
- Inference modes: Deductive, inductive, and abductive reasoning as specifiable capabilities, with declared preferences per sub-mission type.
- Belief revision: Mechanism for reconciling outputs across inference modes into a coherent, revisable confidence state. Bayesian updating provides the formal model; implementations may approximate through calibrated confidence bands, verifier outputs, or source-weighting rules.
- Metacognitive calibration: Self-assessment of confidence, acknowledgement of knowledge boundaries, distinction between computation and pattern-matching.
- Tool-use planning: The cognitive process of selecting and sequencing tool calls. (The tools themselves are infrastructure; the strategy for using them is Mind.)
2.3 Morals
Morals is grounded in deontic logic: the domain of obligations, permissions, and prohibitions. In this architecture, “Morals” does not imply moral agency in the machine. It names the deontic control layer: obligations, permissions, prohibitions, and executable enforcement. Its scope is runtime behaviour: output filtering, validation gates, sandbox enforcement, and refusal logic. The critical distinction from prompt-level instructions is that Morals components are executable. A system prompt line stating “do not execute dangerous commands” is a Mind instruction (a cognitive guideline the model may or may not follow). A sandbox validator that intercepts rm -rf / before execution and raises a PermissionError is a Morals component (a runtime gate the model cannot bypass).
This framing resolves a persistent ambiguity in LLM application design. When behavioural constraints exist only as natural-language instructions in the system prompt, they are suggestions to the model’s reasoning process. They belong to Mind. When constraints are enforced by code that executes independently of the model’s output, they belong to Morals. A mature harness will have both: Mind-level guidance that shapes the model’s intent, and Morals-level enforcement that validates its actions.
The 4M Model specifies Morals as an interface: constraint taxonomy, override hierarchy, and conflict resolution protocol. The spec is agnostic to which ethical framework populates it. A reference implementation may ground its Morals in a specific ethical tradition, demonstrating what coherent Mind-Morals integration looks like when the two modules share ontological ground. The generic spec requires only that a ground exist and that it be explicit. Many AI ethics frameworks move quickly from values to rules without specifying the grounding layer that adjudicates novel cases. The result is brittleness under conflict, ambiguity, or domain transfer.
This also clarifies the relationship between Mission and Morals. Mission without Morals is optimisation: the system pursues its chief end with no constraint on means. Mission grounded in Morals is vocation: the system pursues its chief end rightly. The deontic layer ensures that the teleological layer is not merely effective but legitimate.
Key design properties:
- Executable gates: Code-level validation that intercepts actions before execution (path sandboxing, command pattern matching, network access controls).
- Output validation: Post-generation checks on model output (format compliance, content policy, factual consistency against known sources).
- Refusal logic: Deterministic conditions under which the system declines to act, independent of the model’s willingness.
- Defence in depth: Multiple independent enforcement layers, each sufficient to prevent a class of violation even if other layers fail.
2.4 Memory
Memory is grounded in temporal concerns: what makes the system the same system across time. It provides continuity across turns and sessions, operating at two levels: session memory manages the conversation within a single interaction (history windowing, running summaries, observation masking), while persistent memory retains knowledge across sessions (stored facts, user preferences, project context). The temporal grounding gives Memory its philosophical warrant: without it, each inference call is stateless, and the system has no identity beyond the current prompt.
The module’s core challenge is context engineering under token constraints. An LLM’s context window is finite; Memory must decide what to retain verbatim, what to summarise, what to inject from persistent stores, and what to discard. These decisions are themselves a form of intelligence, but they serve the continuity concern rather than the reasoning concern, placing them in Memory rather than Mind.
Key design properties:
- Session continuity: Token-aware history windowing, observation masking (preserving conversation structure while reducing token cost), and running summaries of evicted turns.
- Persistent store: Typed entries (user facts, behavioural feedback, project context, reference pointers) with create/read/update/delete semantics and time-based expiry.
- Context injection: A build step that assembles a memory block from active persistent entries and injects it into the system prompt, subject to a token budget.
- Projection: The persistent store is the single source of truth; any external representation (flat files, API responses) is a read-only projection.
3. Interaction Model: Hybrid Pipeline with Cross-Cutting Channels
The four modules do not operate in isolation. The 4M Model specifies a hybrid interaction model: a primary inference pipeline that processes each request sequentially, combined with named cross-cutting channels that allow modules to communicate outside the pipeline order.
3.1 Primary Pipeline
The main inference path follows a layered sequence:
Mission (what) --> Mind (how) --> Morals (constrain) --> Output
- Mission determines the active sub-mission, selects guide fragments and tool subsets, and assembles the system prompt skeleton.
- Mind populates the reasoning context: cognitive instructions, metacognitive calibration, and reasoning scaffolding appropriate to the deployment policy.
- Morals applies constraint layers: sandbox validation on tool calls, output validation on generated content, and refusal logic on the assembled response.
- Output is delivered to the user.
Memory participates at both ends of the pipeline: injecting context at the start (persistent recall into the system prompt, session history assembly) and persisting state at the end (appending the exchange to history, storing any new persistent entries).
+------- Memory (inject) -------+
| |
v |
Mission --> Mind --> Morals --> Output
| |
+------- Memory (persist) ------+
3.2 Cross-Cutting Channels
Four named channels enable communication outside the pipeline sequence. Each channel is a specified interface: its direction, trigger condition, and payload type are defined, making it testable and observable.
Channel 1: Memory to Mind (mid-reasoning recall). During reasoning, the Mind module may require information from persistent memory that was not included in the initial context injection. This channel supports on-demand recall: the reasoning process triggers a memory query, and the result is injected into the active context. In tool-calling architectures, this manifests as the model invoking a recall tool mid-conversation.
Channel 2: Mind to Memory (summarisation and persistence decisions). The Mind module generates information that Memory must capture: running summaries of evicted conversation turns, decisions about which facts warrant persistent storage, and updates to existing memory entries. This channel carries the output of metacognitive processes (“this information is worth remembering”) to the persistence layer.
Channel 3: Morals to Mission (constraint-driven adjustment). When Morals enforcement detects a pattern of constraint violations or identifies a mission configuration that conflicts with safety requirements, it signals Mission to adjust. For example, if a sub-mission’s tool subset includes capabilities that Morals has repeatedly blocked, this channel can trigger a sub-mission reconfiguration. This prevents the system from repeatedly attempting actions it will never be allowed to complete.
Channel 4: Mission to Morals (mission-specific constraint activation). Different sub-missions may require different constraint profiles. A coding sub-mission activates file-system sandbox rules; a research sub-mission activates network access controls and source-citation requirements; a creative sub-mission relaxes output format constraints. This channel carries the active sub-mission’s constraint requirements to the Morals module.
3.3 Channel Properties
Each cross-cutting channel satisfies three properties:
- Named: The channel has an explicit identifier, making it referenceable in documentation, logging, and test specifications.
- Directional: Each channel has a defined source and sink module, preventing circular dependencies in the primary interaction model.
- Observable: Channel activations are logged with their trigger condition and payload summary, supporting debugging and audit.
4. The Means Layer: Execution Substrate
The 4M Model describes the agent’s cognitive architecture: how it reasons, what it pursues, what constrains it, and what it remembers. A natural question arises: where does tool orchestration, API invocation, file I/O, sandbox enforcement, and error recovery belong?
The answer is that these are not a fifth M. They belong to a separate architectural layer: Means. The relationship between 4M and Means is directional:
+-----------------------------+
| 4M Harness | <-- cognitive architecture
| Mission . Mind . Morals . |
| Memory |
+-------------+---------------+
| directs
v
+-----------------------------+
| Means | <-- execution layer
| Tools . APIs . Sandbox . |
| I/O . Error Recovery |
+-----------------------------+
4M decides what to do; Means handles how it gets done. Mind reasons about which tool to use; Means handles how that tool executes, what happens when it fails, and what the agent is permitted to touch. The distinction is analogous to the difference between a steering system and an engine: the steering system (4M) controls direction; the engine (Means) provides motive force. They are coupled but architecturally distinct.
This separation yields a practical benefit: Means is swappable. A single 4M harness specification can drive different Means implementations:
- Local tools: file system access, shell execution, local databases
- Cloud APIs: managed services, third-party integrations, SaaS endpoints
- Air-gapped environments: on-premise inference, no external network access
The same Mission, Mind, Morals, and Memory configuration produces consistent cognitive behaviour regardless of which Means implementation provides the execution substrate. This is how dual-mode deployments (connected vs. air-gapped) fall out naturally from the architecture rather than requiring special-case handling.
Means is specified as an interface contract: the set of capabilities that a conforming execution layer must provide, the error semantics it must respect, and the observability hooks it must expose. The 4M harness depends on the Means interface, never on a specific implementation. This contract is the boundary between the cognitive architecture and the world.
5. Design Principles
The 4M Model is guided by five principles that constrain implementation choices.
5.1 Separation of Concerns
The modules are conceptually orthogonal but operationally coupled through explicit interfaces (the cross-cutting channels of Section 3.2). Each module addresses exactly one governing question. A change to Mission (what the system does) should not require changes to Memory (what it remembers) or Morals (what it must not do). Separation is validated by a simple test: can each module’s configuration be modified independently without breaking the others? If adding a new sub-mission requires modifying the memory schema, the boundary has been violated. Where modules must communicate (Mission selecting Morals constraint profiles, Memory supplying priors to Mind), that coupling is channelled through named, directional, observable interfaces rather than implicit dependency.
5.2 Mechanism Neutrality
Modules are defined by concern, not by implementation mechanism. Mission may be realised through system prompt text, a configuration file, or a database of intent-to-guide mappings. Memory may use SQLite, Redis, a vector store, or in-memory data structures. Morals may employ regex pattern matching, AST analysis, or a secondary LLM call. The 4M Model prescribes the what, not the how.
5.3 Defence in Depth
Morals enforcement must not depend on a single mechanism. A constraint that exists only in the system prompt is a suggestion; a constraint that is additionally enforced by a code-level gate is a guarantee. The architecture requires that safety-critical constraints have at least two independent enforcement points: one in Mind (cognitive guidance) and one in Morals (executable validation).
5.4 Single Source of Truth
Each category of state has exactly one authoritative store. Persistent memory lives in the database; any file or API projection is derived and read-only. Session state lives in the conversation history; any summary is a lossy compression, not a replacement. Configuration lives in the environment or configuration store; runtime state is derived. Violations of this principle produce consistency bugs that are difficult to diagnose.
5.5 Testability
Every module boundary and cross-cutting channel is an interface that can be tested in isolation. Mission can be tested by verifying that a given intent produces the expected guide fragments and tool subsets. Mind can be tested by evaluating reasoning quality on benchmark prompts. Morals can be tested by submitting known-dangerous inputs and verifying rejection. Memory can be tested by asserting round-trip consistency of stored and retrieved entries. Cross-cutting channels can be tested by simulating their trigger conditions and verifying the expected payload and downstream effect.
6. Reference Implementation: ThinxS
The ThinxS project implements the 4M Model for a self-hosted LLM deployment. The following sections map each module to its concrete realisation, demonstrating that the abstract architecture accommodates the engineering constraints of a real system.
6.1 Mission in ThinxS
Base mission is defined in the mode header: a static identity block (“You are ThinxS, the ThinxAI assistant”) combined with a capabilities declaration and default behavioural tone. Four named modes (default, technical, creative, research) provide variant base missions with distinct temperature and token budget parameters.
Sub-missions are driven by a Tier 1 deterministic intent classifier (tools/context_sensor.py). The classifier scores incoming messages against keyword sets for six intent categories (coding, document, research, planning, git, conversation) and applies hysteresis requiring two consecutive matching signals before switching the active intent. This design achieves sub-millisecond classification latency at zero inference cost, a critical property for self-hosted deployments where the inference endpoint is a shared resource.
Each intent maps to a subset of guide fragments (INTENT_GUIDES) and tool definitions (INTENT_TOOLS), reducing context noise by presenting only mission-relevant information to the model. The conversation intent serves as a fallback that includes all guides and tools.
6.2 Mind in ThinxS
Cognitive instruction is distributed across guide fragments selected by Mission. The behavioral_core guide encodes metacognitive calibration: distinguish computation from pattern-matching, flag confidence levels, acknowledge knowledge boundaries, prefer accuracy over approval. Mode-specific footers adjust reasoning priorities (technical mode prioritises precision; creative mode encourages varied expression; research mode demands evidence-inference distinction).
The tool-calling loop (_process_chat_job()) implements a ReAct-style reasoning cycle with a maximum of ten iterations. The model selects tools, observes results, and decides whether to continue or produce a final response. This iterative process is the runtime expression of Mind: the model is reasoning about how to accomplish the Mission using available tools, subject to Morals constraints on those tools.
6.3 Morals in ThinxS
Constraint enforcement operates through four independent layers, implementing defence in depth:
-
Path sandboxing (
tools/sandbox.py): All file operations are validated against an allowlist of directories. Paths outside the sandbox raisePermissionErrorbefore any file system access occurs. -
Dangerous command blocking (
tools/sandbox.py): Shell commands are matched against a pattern list of destructive operations (rm -rf /,mkfs,dd if=, fork bombs, shutdown sequences). Matches are rejected before execution. -
Network access control (
server.py): Web fetch and search operations resolve target hostnames and reject private, loopback, reserved, and link-local IP addresses, preventing server-side request forgery. -
Tool-call validation (
tools/registry.py): Required parameters are validated before tool execution; malformed calls return structured error responses rather than propagating to tool handlers.
The system prompt contributes a fifth, non-executable layer: behavioural guidance that shapes the model’s intent (truth over satisfaction, source citation requirements, confidence flagging). This layer belongs to Mind in the 4M taxonomy but complements the executable Morals layers by reducing the frequency of constraint violations that the runtime gates must catch.
6.4 Memory in ThinxS
Session memory implements a three-zone token budget model:
| Zone | Content | Eviction Policy |
|---|---|---|
| Pinned | System prompt, tool definitions, persistent memory block | Never evicted |
| Summary | Running summary of evicted turns | Regenerated on each eviction cycle |
| Verbatim | Recent messages with masked observations | Oldest turns evicted when budget exceeded |
Observation masking (mask_observations()) replaces tool result content in older messages with a truncation marker while preserving the message structure. This can significantly reduce token load in long-running agent sessions by preserving conversational structure while compressing tool-result payloads, without losing the scaffolding that helps the model maintain coherence.
Running summaries are generated via LLM-based summarisation of evicted turns (with a heuristic fallback for resilience), producing a cumulative summary that grows as the conversation extends beyond the verbatim window.
Persistent memory uses SQLite (WAL mode) as the single source of truth. Entries are typed (user, feedback, project, reference) with type-specific TTL policies (project entries expire after 90 days; others persist indefinitely). The build_context_block() function assembles active entries into a <memory> block injected into the system prompt, subject to a configurable token budget.
A flat-file projection (memory.md) is regenerated after every write operation, providing a human-readable view of the persistent store. This file is explicitly read-only; the system prompt instructs the model to use structured action tags ([ACTION:remember\lvert...\rvert]) for memory writes, ensuring all mutations flow through the SQLite store.
6.5 Cross-Cutting Channels in ThinxS
Memory to Mind: Persistent memory is injected into the system prompt at the start of each inference call (get_effective_system_prompt()). Mid-conversation recall is supported through the /recall command and semantic_search tool, which query the SQLite store and inject results into the conversation as tool results.
Mind to Memory: The model writes to persistent memory via action tags processed by process_action_tags(). Running summaries are generated by the Mind module (LLM inference) and stored by the Memory module as session state.
Mission to Morals: Each intent activates its associated tool subset (INTENT_TOOLS). Tools excluded from the active subset are not presented to the model, preventing tool calls that the Morals layer would reject. The coding intent activates file-system tools (and their associated sandbox rules); the research intent activates web tools (and their associated network access controls).
Morals to Mission: The circuit breaker (_check_circuit_breaker()) approximates this channel at the infrastructure boundary. After five consecutive inference failures, the system suspends processing for 60 seconds rather than continuing to issue failing requests. Strictly speaking, this is Means-level resilience with Morals-to-Mission implications; a fuller implementation would adjust the active sub-mission or tool subset in response to repeated constraint violations.
7. Comparison with Existing Frameworks
The 4M Model is not the first attempt to structure LLM application architecture. It builds on and differs from several existing approaches.
LangChain (LangChain, 2023) provides a toolkit of composable abstractions (chains, agents, memory, retrievers) but does not prescribe a separation of concerns at the harness level. A LangChain application may implement all four 4M modules, but the framework does not distinguish between them; a chain that retrieves context, reasons about it, and validates output is a single undifferentiated unit. The 4M Model adds the architectural layer that LangChain’s abstractions leave implicit.
DSPy (Khattab et al., 2024) focuses on optimising prompt programs through learned examples and automated tuning. Its concern is primarily the Mind module: improving reasoning quality through systematic prompt optimisation. The 4M Model is complementary; DSPy techniques could be applied within the Mind module without affecting Mission, Memory, or Morals.
Anthropic’s system prompt guidelines (Anthropic, 2025) recommend structuring system prompts with distinct sections for identity, instructions, constraints, and examples. This is structurally similar to the Mission/Mind/Morals decomposition but remains within the system prompt. The 4M Model extends the separation beyond the prompt to the entire harness, encompassing runtime enforcement, persistent state, and cross-module communication.
AutoGPT and similar agent frameworks (Significant Gravitas, 2023) implement a loop of reasoning, tool use, and memory that maps loosely to Mind, Mission, and Memory. However, they typically lack a distinct Morals module; constraint enforcement is embedded in the reasoning prompt and the tool implementations, with no architectural separation or defence-in-depth requirement.
7.1 Comparative Summary
| Framework | Primary Contribution | 4M Diagnosis |
|---|---|---|
| LangChain | Component/tool orchestration | Supplies Means and partial Memory/Mind abstractions, but does not enforce 4M separation |
| DSPy | Declarative optimisation of LM programs | Strongly Mind-oriented: prompt/program optimisation within the epistemic layer |
| ReAct | Interleaved reasoning and action | Mind pattern using Means feedback; no distinct Mission, Morals, or Memory |
| AutoGPT | Agent loop with memory and tools | Loose Mission-Mind-Memory loop; weaker explicit Morals |
| Anthropic prompting guidance | Prompt structuring | Prompt-level decomposition; does not extend to runtime enforcement or persistent state |
8. Limitations and Future Work
The 4M Model as presented has several limitations that warrant further investigation.
Empirical validation: The architecture is derived from engineering experience and first principles rather than controlled experimentation. Comparative studies measuring the effect of 4M-structured harnesses on task completion, safety, and maintainability against unstructured alternatives would strengthen the model’s claims.
Channel formalisation: The cross-cutting channels are currently specified informally. A formal interface definition language or contract specification (in the tradition of design-by-contract; Meyer, 1997) would enable automated verification of channel compliance and support tooling for channel-aware testing.
Multi-model architectures: The current model assumes a single primary LLM. Architectures employing multiple models (e.g., a small classifier model for Mission, a large model for Mind, and a specialised model for Morals validation) introduce additional interaction patterns that the current channel model does not fully address.
Dynamic Morals: The current model treats Morals constraints as relatively static (configured at deployment time, activated by Mission). Adaptive constraint systems that learn from observed violations and adjust enforcement thresholds would require a richer model of the Morals module’s internal state.
9. Conclusion
The 4M Model provides a vocabulary and structure for the engineering work that surrounds LLM inference. By grounding each module in a distinct philosophical domain (telos, epistemics, deontics, temporality), decomposing harness concerns into four modules with separated concerns, specifying their interactions through a hybrid pipeline with named cross-cutting channels, and separating the cognitive architecture from the execution substrate (Means), it transforms an ad hoc collection of prompt fragments, tool handlers, and state management into a principled architecture.
The philosophical grounding is not incidental. It gives each module a non-overlapping jurisdiction that resolves ambiguity about where design decisions belong. Mind’s internal structure (deductive, inductive, and abductive inference unified by a Bayesian belief-revision framework) provides the formal model for confidence signaling; concrete implementations may approximate this through calibrated confidence bands, verifier outputs, or source-weighting rules. The Means layer’s separation from the cognitive architecture enables deployment portability: the same 4M specification drives local, cloud, or air-gapped execution environments without modification.
The model is deliberately generic. It does not prescribe programming languages, databases, model providers, or ethical frameworks. It does prescribe that the four concerns be separated, that their boundaries be testable, that constraint enforcement be executable rather than merely advisory, that state management follow single-source-of-truth principles, and that the Morals module be grounded in an explicit ethical framework rather than an ad hoc rule list. These prescriptions are informed by the engineering reality that LLM harnesses are software systems, and software systems benefit from separation of concerns.
The ThinxS reference implementation demonstrates that these prescriptions are practical. A self-hosted deployment with deterministic intent classification, four-layer constraint enforcement, token-aware context management, and SQLite-backed persistent memory implements all four modules and all four cross-cutting channels within a single-server architecture. The 4M Model did not require exotic infrastructure; it required clarity about which code serves which concern.
Appendix: 4M Conformance Checklist
The following checklist provides a practical diagnostic for evaluating whether a harness implementation conforms to the 4M architecture.
- Module coverage: Does every active behaviour map to Mission, Mind, Morals, Memory, or Means?
- Executable enforcement: Are safety-critical constraints enforced outside the model (code-level gates), not only in the prompt?
- Mission coherence: Are sub-missions validated against the base mission? Can the system reject mereologically incoherent requests?
- Single source of truth: Is persistent memory governed by a single authoritative store, with all other representations derived?
- Grounded confidence: Are confidence signals derived from evidence, retrieval, verification, or explicit calibration rather than model self-report alone?
- Observable coupling: Are cross-module channels named, directional, and observable in logs or traces?
- Means independence: Can the execution layer (Means) be swapped without rewriting the cognitive architecture (4M)?
Research Programme
This article is the core theory of the Harness Engineering research programme, structured as a Lakatosian programme with the 4M Model as its hard core. The programme repository contains the full Lakatos framing (hard core, protective belt, positive and negative heuristics), evaluation materials, and pointers to reference implementations. Future work on channel formalization, multi-model archetypes, tiered adoption, and dynamic Morals will be developed there.
References
Anthropic (2025) Prompt engineering: System prompts. Available at: https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/system-prompts (Accessed: 20 April 2026).
Bass, L., Clements, P. and Kazman, R. (2012) Software Architecture in Practice. 3rd edn. Boston: Addison-Wesley.
LangChain (2023) LangChain: Framework for building agents and LLM-powered applications. Available at: https://github.com/langchain-ai/langchain (Accessed: 20 April 2026).
Khattab, O. et al. (2024) ‘DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines’, in Proceedings of the International Conference on Learning Representations (ICLR 2024).
Meyer, B. (1997) Object-Oriented Software Construction. 2nd edn. Upper Saddle River: Prentice Hall.
Significant Gravitas (2023) AutoGPT: An autonomous GPT-4 experiment. Available at: https://github.com/Significant-Gravitas/AutoGPT (Accessed: 20 April 2026).
Yao, S. et al. (2023) ‘ReAct: Synergizing Reasoning and Acting in Language Models’, in Proceedings of the International Conference on Learning Representations (ICLR 2023).
Comments
Sign in with GitHub to comment, or use the anonymous form below.